하지만, 정수값을 가지는 가중치가 있고 N = 10000개라면 int[10000][10000] 의 인접 행렬을 생성해야하는데 이는 1억개임. int형이 1억개면 메모리는 4억바이트가 된다. 메모리 조건이 400MB보다 크면 상관없지만 주로 이보다 작아서 인접 행렬을 사용할 수 없다. → 인접 리스트를 사용해야함
2. 인접 리스트
각 정점에 대한 인접 정점들을 순차적으로 표현하여 하나의 정점에 대한 인접 정점들을 각각 노드로 연결하는 리스트로 저장한다.
정점도 어느정도 있고 간선도 많으면( 밀집 그래프), 인접 리스트는 하나씩 전부 들여다 봐야하기때문에 효율성이 좋지 않다. 또한, 입력이 2차원식으로 들어온다면 → 인접 행렬을 사용해야한다
3. 간선 리스트
두 정점에 대한 간선 그 자체를 객체로 표현하여 리스트로 저장하며, 간선을 표현하는 두 정점의 정보를 나타낸다(시작 정점, 끝 정점)
간선(시작 정점, 끝 정점)의 정보를 객체로 표현하여 리스트에 저장. 즉, 간선 정보를 리스트로 유지
즉, 노드가 많으면 인접 리스트를 간선이 많으면 인접 행렬을 사용
그래프 표현
자바에서 그래프를 표현하는 방식에는 여러가지가 있다. 나는 주로 2D 배열을 사용하여 인접 배열 형태로 나타내는데, 이번 패스트캠퍼스 강의에서 HashMap으로 표현하는 방법을 배웠는데 인상적이였다.
ArrayList를 잘 활용하는 편이 아니라, 인접리스트 구현이 많이 어려웠는데 강의를 듣고나니 이해가 많이 됬다. 물론 문제에 접목 가능한 정도인지는 백준을 열어봐야..
HashMap<String , ArrayList<String>> graph = new HashMap<>();
graph.put("A", new ArrayList<String>(Arrays.asList("B", "C")));
graph.put("B", new ArrayList<String>(Arrays.asList("A", "D")));
graph.put("C", new ArrayList<String>(Arrays.asList("A", "G", "H", "I")));
//이하 생략
1. HashMap 을 사용하여 그래프 표현
2. put () 을 사용하여 각 노드 당 연결된 노드를 삽입
3. Arrays.asList() 를 사용하면, 쉽게 리스트를 만들 수 있다.
너비 우선 탐색
본 강좌에서는 visited와 needVisit 리스트 두개를 사용하여 방문처리 리스트와 방문중인 큐를 리스트로 구현하였는데, 나는 큐 방식이 더 쉽다고 느끼기에 큐를 사용하여 BFS를 구현해 보겠다.
보통 visited 리스트는 boolean 형태의 배열로 표현하는데, 리스트를 사용하니 .contains()를 사용할 수 있어서 편했다.
설명을 주석처리 해놨지만, 큐와 방문처리를 할 리스트를 구현한 후 시작점을 큐에 놓고 큐가 빌때까지 방문하지 않은 노드들을 큐에 담아 반복한다.
만일 아래 그래프라면,
1. A 를 큐에 담는다 (start node)
2. 반복문 시작:
3. 큐의 맨 앞을 뺀다 -> A
4. 방문중인가? no -> A를 방문처리해주고, A와 연결된 B와 C를 큐에 넣는다
5. 반복문으로 돌아가서 큐의 맨 앞을 뺀다 -> B
6. 방문중인가? no -> B를 방문처리 해주고, B와 연결된 D,E,F를 큐에 넣는다
현재 큐 상태 :[C, D, E, F]
7. 반복문으로 돌아가서 큐의 맨 앞을 뺀다 -> C
8. 방문 중인가 ? no -> C의 자식인 H, I ,G를 큐에 삽입
현재 큐 상태 : [ D, E, F, H, I, G]
위 노드들은 자식들이 없기 때문에 순차적으로 빠지고 나면 최종 순서는
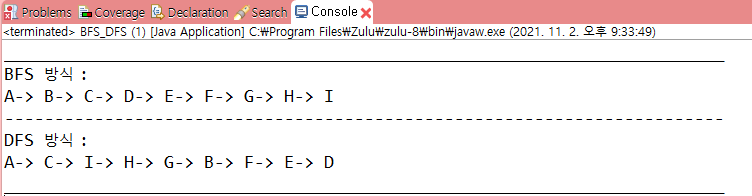
A -> B -> C -> D -> E -> F-> G -> H -> I 가 되는 것을 볼 수 있다
위 프로그램을 돌려보면, 성공적으로 BFS 가 구현됨을 확인해 볼 수 있다.
깊이 우선 탐색
주로 재귀 형태로 쓰인 깊이 우선 탐색을 많이 봤는데, BFS와 거의 동일한 방식으로 사용하는 방법을 본 강좌에서 가르쳐주었기 때문에 너무 편리했다.
항상 너비 우선 탐색만 사용하다가 DFS가 생각이 안나서 못푼 문제가 있는데 이가 갈린다... BFS 구현과 한줄 빼고 같다고 보면 된다. BFS는 큐를 사용했지만, DFS는 스택 자료 구조를 사용한다. 즉, BFS에서 current Node를 poll 해서 맨 앞에 들어간 원소를 빼냈다면 DFS는 스택(리스트)의 가장 마지막 원소를 빼내면 된다 !